Hierarchical Bayesian Inference (Discrete Method)¶
Introduction¶
It is recommended to read Introduction and Model Specification sections of Generating Mock Posterior Estimates tutorial to get familiar with the model and the data used in this tutorial.
Priors¶
Priors are also NumPyro distributions. They are provided through a json file. Each key corresponds to a model parameter and its value is a dictionary, which specifies the type of distribution and its parameters. For example, the prior for \(x\) is given by a normal distribution with mean 2 and standard deviation 3.
then the json file will look like,
{
"x": {
"dist": "Normal",
"loc": 2,
"scale": 3
}
}
Prior distributions and constants for the model parameters used in this tutorial are,
User can provide any NumPyro distribution which takes only scalar parameters. Their json
representation is saved in
priors.json,
{
"log_rate_0": {
"dist": "Uniform",
"low": -11.5,
"high": 11.5
},
"alpha_pl_0": {
"dist": "Uniform",
"low": -5.0,
"high": 5.0
},
"beta_pl_0": {
"dist": "Uniform",
"low": -5.0,
"high": 5.0
},
"mmin_pl_0": {
"dist": "Uniform",
"low": 1.0,
"high": 20.0
},
"mmax_pl_0": {
"dist": "Uniform",
"low": 30.0,
"high": 100.0
}
}
MCMC Sampler Configurations¶
NumPyro¶
We provide No U-Turn Sampler (NUTS) through NumPyro as one of the MCMC samplers.
The configuration for the sampler is also provided through a json file. Configuration
has two sub-configurations, one for the NUTS kernel and another for the MCMC sampler.
MCMC configuration are provided under the key mcmc while NUTS kernel configurations
are provided under the key kernel. For example, if we want to set the maximum tree
depth of the NUTS kernel to 6 and number of warmup steps to 3000, number of samples
to 1000, number of chains to 10, thinning to 1, chain method to “parallel”, enable
progress bar and JIT model args, then the json file will look like below.
{
"kernel": {
"max_tree_depth": 6
},
"mcmc": {
"num_warmup": 3000,
"num_samples": 1000,
"num_chains": 10,
"thinning": 1,
"chain_method": "parallel",
"progress_bar": true,
"jit_model_args": true
}
}
Please see the
numpyro.infer.MCMC
and
numpyro.infer.NUTS
for more details on the available configurations.
These configurations are saved in
numpyro_config.json.
Then you can run the following command to perform Hierarchical Bayesian Inference using
NumPyro NUTS sampler.
n_sage_n_pls_m_gs \
--seed 37 \
--n-pl 1 \
--n-g 0 \
--posterior-regex "../generating_mock_posterior_estimates/data/realization_0/posteriors/event_*.dat" \
--posterior-columns mass_1_source mass_2_source \
--pmean-cfg pmean.json \
--prior-cfg prior.json \
--sampler-cfg numpyro_config.json \
--n-buckets 10
seedis the random seed for reproducibility.posterior-regexis the regex pattern to locate posterior samples of individual events.posterior-columnsare the columns in the posterior samples corresponding to primary mass, secondary mass and eccentricity.pmean-cfgis the json file containing the detector sensitivity information.prior-cfgis the json file containing the prior distributions of the population parameters.sampler-cfgis the json file containing the MCMC sampler configurations.n-bucketsis an optimization parameter to speed up the likelihood evaluations.
FlowMC¶
Similarly, we can use Normalizing flows enhanced MALA (FlowMC) as the MCMC sampler.
The configuration for FlowMC is also provided through a json file and saved in
flowMC_config.json.
We will talk about the various configurations in detail in another tutorial.
{
"data_dump": {
"n_samples": 10000
},
"bundle_config": {
"chain_batch_size": 0,
"n_chains": 100,
"batch_size": 10000,
"n_epochs": 4,
"n_max_examples": 200000,
"history_window": 2000,
"n_NFproposal_batch_size": 50,
"n_global_steps": 100,
"n_local_steps": 100,
"n_production_loops": 10,
"n_training_loops": 10,
"global_thinning": 4,
"local_thinning": 4,
"local_sampler_name": "hmc",
"step_size": 0.01,
"condition_matrix": 1.0,
"n_leapfrog": 5,
"rq_spline_hidden_units": [64, 64],
"rq_spline_n_bins": 10,
"rq_spline_n_layers": 8,
"rq_spline_range": [-10.0, 10.0],
"learning_rate": 0.001,
"verbose": false
}
}
Then you can run the following command to perform Hierarchical Bayesian Inference using FlowMC sampler.
f_sage_n_pls_m_gs \
--seed 37 \
--n-pl 1 \
--n-g 0 \
--posterior-regex "../generating_mock_posterior_estimates/data/realization_0/posteriors/event_*.dat" \
--posterior-columns mass_1_source mass_2_source \
--pmean-cfg pmean.json \
--prior-cfg prior.json \
--sampler-cfg flowMC_config.json \
--n-buckets 10
Analysis of Results¶
Sat Nov 1 16:23:27 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 575.57.08 Driver Version: 575.57.08 CUDA Version: 12.9 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce RTX 4090 On | 00000000:01:00.0 Off | Off |
| 0% 36C P8 35W / 450W | 40MiB / 24564MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| 0 N/A N/A 1286 G /usr/lib/xorg/Xorg 9MiB |
| 0 N/A N/A 1474 G /usr/bin/gnome-shell 10MiB |
+-----------------------------------------------------------------------------------------+
FlowMC Results¶
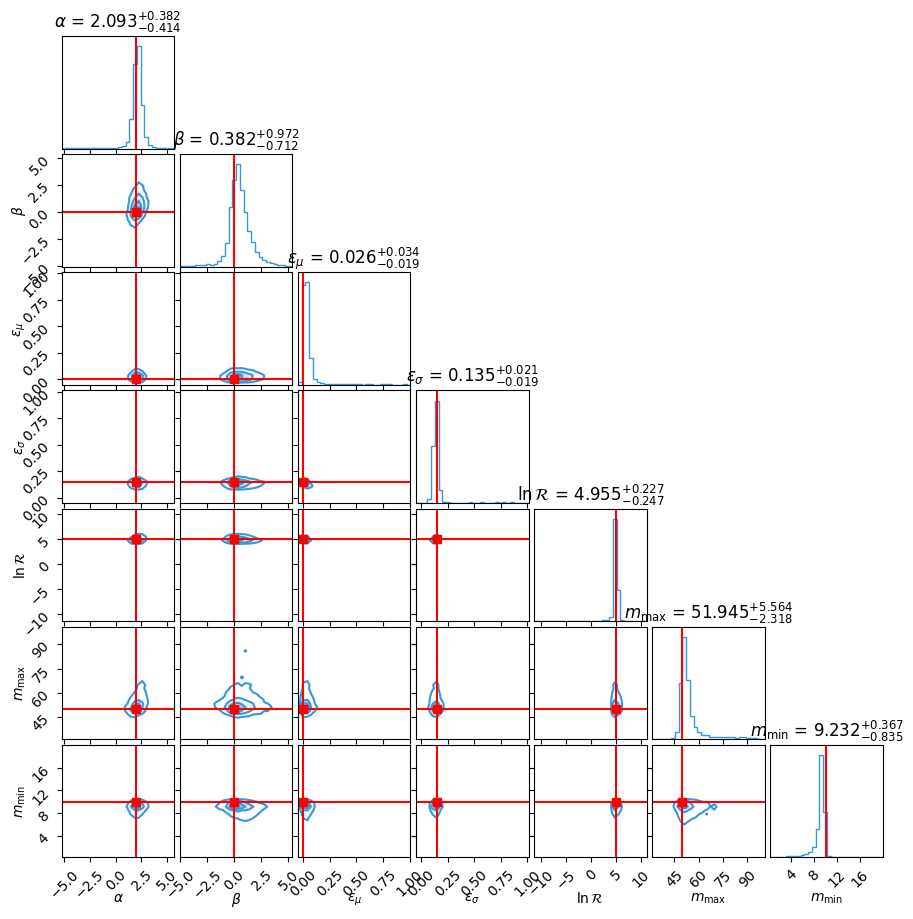
NumPyro Results¶
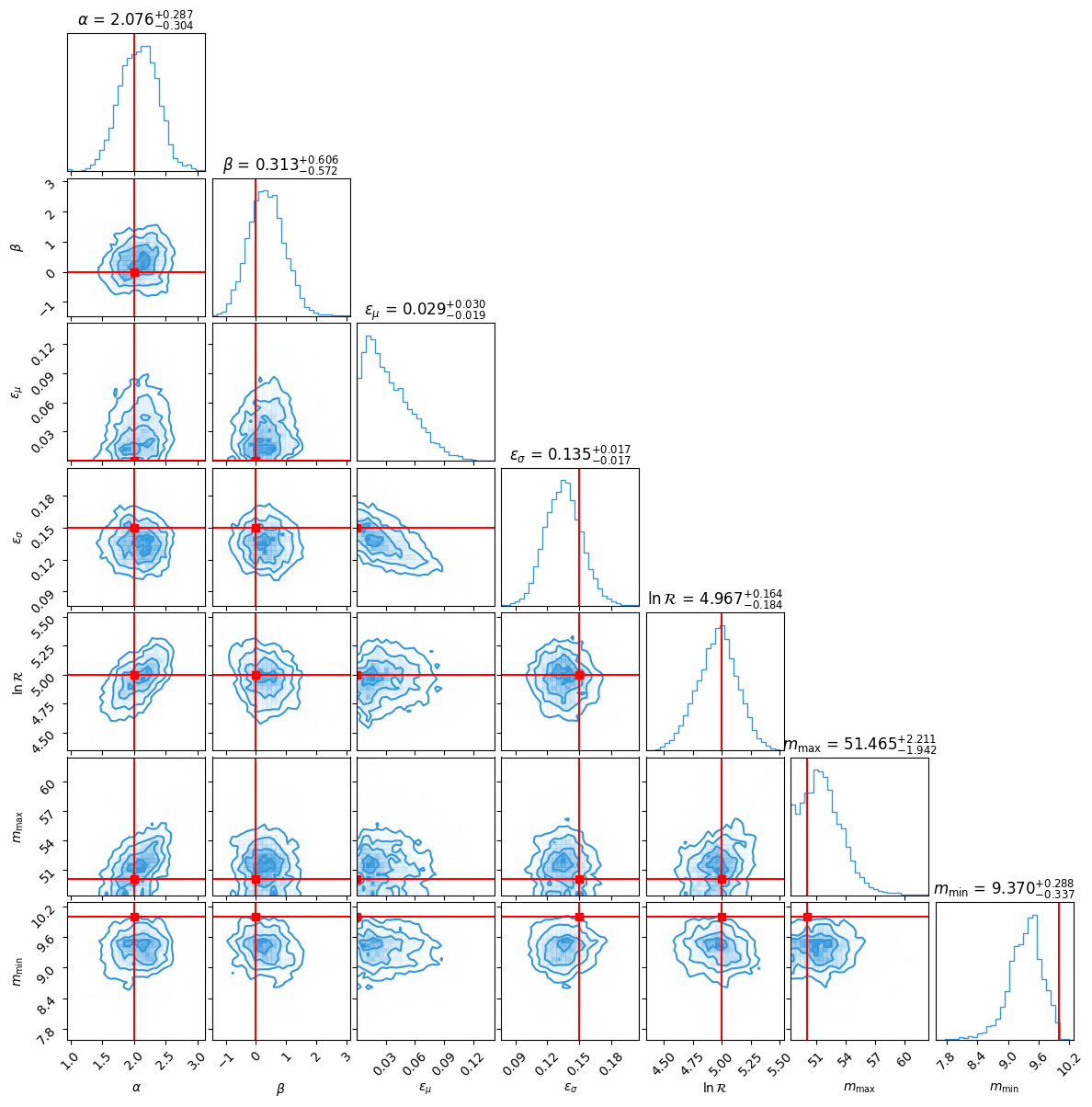
All the code and files used in this tutorial can be found in hello-gwkokab/hbi_discrete_method.